Generate Novel Identities and Controlling Pose and Expression
TL;DR: In virtual and augmented reality applications, artists need geometrical control over head pose and facial expressions. In this work — VariTex — we combine explicit 3D geometry with deep image sampling networks in UV space. This allows synthesizing entirely novel identities with full control over head pose and facial expression. Interestingly, the network can generate extreme head poses but is trained in a self-supervised fashion with mostly frontal images.

Introduction
Let’s assume that we are designers for virtual or augmented reality applications in Microsoft Mesh, Oculus, Google AR/VR, etc. Our job is to design a photorealistic virtual assistant that welcomes new players and shows them around in a virtual world. Players should be able to customize the looks of the virtual assistant to their wishes. How should we approach this challenge?
Solving this task with traditional computer graphics is very difficult and requires a lot of manual work. Some companies have made large efforts to generate photorealistic humans, e.g., Unreal Engine’s Metahumans, Reallusion’s Character Creator, Microsoft’s Face Synthetics, and Disney’s Digital Humans. These systems are highly complex because they need to explicitly model physical properties like the reflection and refraction of light that hits the skin. We are asking: How can the power of Deep Learning help implicitly learn photorealistic appearance from examples?
Deep Generative Models
Current deep generative models, like StyleGAN, produce impressive results. Could you tell which of these images is fake?

In fact, all the images above are fake — the level of photorealism is stunning. Yet, these methods produce static images without any explicit geometry making it difficult to animate them. If such methods should help us in our task to build a virtual assistant, we need explicit control over the generated identity, head pose, and facial expression.
Textures and UV Mapping
This can be done by incorporating explicit 3D geometry into the deep learning model and synthesizing appearance in a UV texture space. The texture layout is independent of pose and expression. It establishes a mapping between texels (pixels in the texture) to the face mesh vertices in 3D space — called UV mapping. Intuitively, the same texel in the texture image corresponds to the same point on the face surface for any pose and expression.


Reconstructing facial geometries from images and videos often yields noisy estimates. To make this work in a deep learning setting, the model needs to be robust towards imperfect geometries. A solution is to replace classical RGB textures with more expressive neural textures, as introduced by the paper Deferred Neural Rendering. The original approach requires hundreds of training images for each person. In our scenario, players should be able to generate novel identities so we need a more generic system. How can we generalize these concepts and create entirely unseen identities?
Variational Neural Textures
We learn a generative model of neural face textures called VariTex: Variational Neural Face Textures. Instead of optimizing one texture given many images from one identity (as in Deferred Neural Rendering), we learn variational textures from a dataset of single images from many identities and train in a self-supervised manner from single-view images alone. At inference time, we can sample neural latent codes and generate neural textures for novel identities.

The following video explains the neural rendering pipeline (1:28–2:38).
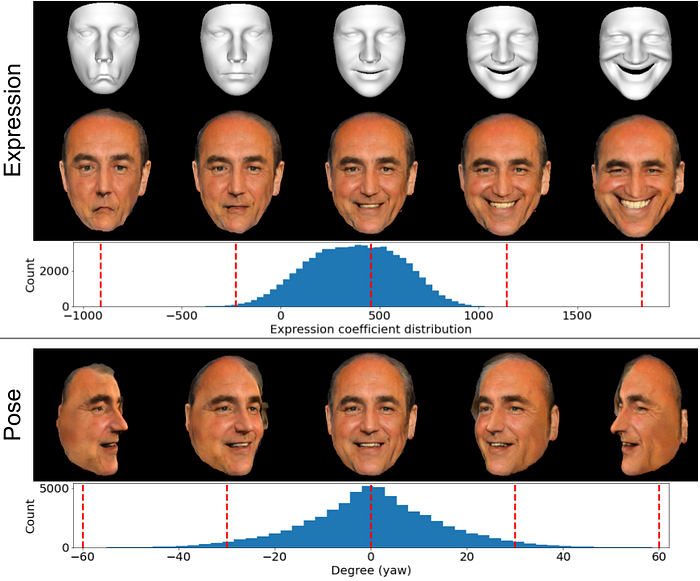
Where does the consistency come from and why can VariTex render extreme poses? The strict mapping from texture space to the surface in 3D enables learning from very few examples. The texture space has the same layout for all identities, expressions, and poses. It is therefore much easier to learn from few examples.
This approach allows generating novel identities and rendering extreme poses and expressions. This even works for highly unnatural facial geometries (top) and head poses outside the training distribution (bottom).
Limitations

The current approach requires a known 3D surface with a UV parameterization. Animating regions where the face model does not provide geometry yields inconsistent animations, e.g., for the hair.
A solution to this could be to use a 3D model of the full head that includes the hair and mouth interior. There exist multiple exciting works trying to solve this problem of reconstructing full heads (see links below).

Conclusion
We envision a technology that helps digital artists design and animate customizable virtual avatars. Such avatars can facilitate more natural interactions between humans and computer systems, in particular in virtual and augmented reality applications.
Our work — VariTex — takes a step towards this goal. VariTex is a deep generative model for neural face textures, which allows synthesizing entirely novel identities with full control over head pose and facial expression. Interestingly, the network can generate extreme head poses but is trained in a self-supervised fashion with mostly frontal images.
Thank you for reading! If you are interested, you can find out more about our work following these links:
If you are interested in animating full body humans, make sure to check out this blog post.
Our work has been heavily inspired by Deferred Neural Rendering and Neural Voice Puppetry. These exciting papers model full heads in 3D: FLAME, i3DMM, H3D-Net.
If you find our work helpful, please consider citing it as
@inproceedings{buehler2021varitex,
title={VariTex: Variational Neural Face Textures},
author={Marcel C. Buehler and Abhimitra Meka and Gengyan Li and Thabo Beeler and Otmar Hilliges},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2021}
}