Shape-aware Multi-Person Pose Estimation from Multi-View Images
Introduction:
Markerless human motion capture is one of the fundamental problems in computer vision. While much impressive progress has been made recently in 2D/3D pose estimation of a single person, these methods can’t be directly extended and applied in a situation when multiple people are interacting with each other closely. Imagine that you are a designer of an unmanned supermarket like Amazon Go, the most important task is to obtain accurate poses of multiple people in the shop accurately and fast to help machines better understand human behaviors. In this post, we mainly ask this question: how can we estimate multiple 3D human poses/shapes from sparse multi-view images?

The Challenge:
When multiple people are interacting with each other at close range, we can expect a multitude of difficulties due to the heavy and complicated occlusions and depth ambiguities. The strong occlusions make 2D joint detections noisy and sometimes missing in the image. Leveraging multiple cameras is a good idea to alleviate occlusions and provide stereo cues for accurate 3D triangulation, but it will also bring new challenges to us for associating joints from different views into individual instances. Further, directly learning end-to-end models from the labeled data can be accurate when training and test distributions are similar, but these methods suffer from generalization issues in the absence of labeled multi-view multi-person data for this task. It remains unclear how we can solve data association and enhance the robustness of the learned model by leveraging the human prior.

Our Approach:
To solve these two challenges, our method mainly contains two stages: 3D human proposal generation and shape-aware 3D pose optimization.

In the first part, we are motivated by the insight: if a joint has been predicted accurately in several views, then there will be a dense cluster of 3D candidates for the joint, and low confidence, isolated candidates can be discarded. Thus we first triangulate 2D joints with the same part label into 3D space and develop a voting-based algorithm for clustering joint candidates from partial observations. Through this process, we can aggregate 2D detections in a 3D space and associate them into individual instances according to certain reliable joints like the hip. Finally, PAFs detected in images are used to filter some joints from other closely interacting people.

In the second part, this coarse 3D localization step is followed by a refinement step to correct poses and fill in missing joints via an optimization scheme that leverages multi-view constraints directly, where high confidence 2D observations are available, and regularizes the low-confidence 3D poses via a parametric body model (SMPL). In this optimization process, both the initial 3D pose proposals and SMPL parameters are optimized in an alternating manner. This is motivated by the insight: a good estimate of 3D poses helps in fitting SMPL, while better SMPL estimates make 3D poses more robust.
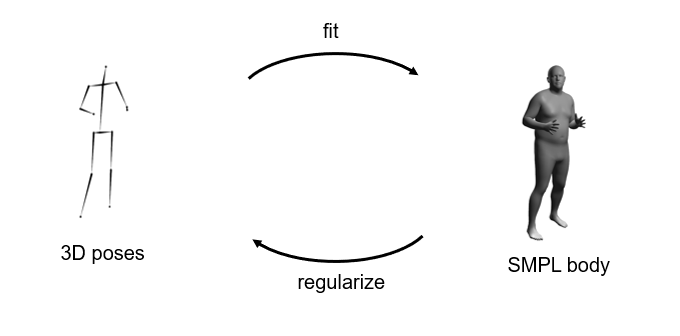
Importantly, the SMPL parameters are aligned directly to the updated 3D observations via the learned per-parameter gradient method whereby the gradient is estimated by a neural network. This enables us to leverage existing motion capture datasets (AMASS) to learn body priors without requiring labeled multi-view multi-person data. Comparing with traditional optimization methods, our method converges fast and achieves more accurate performance.

Our method is general since we only leverage off-the-shelf 2D pose detector and body pose priors distilled from motion capture datasets. SOTA performance is achieved on public datasets.
Result:
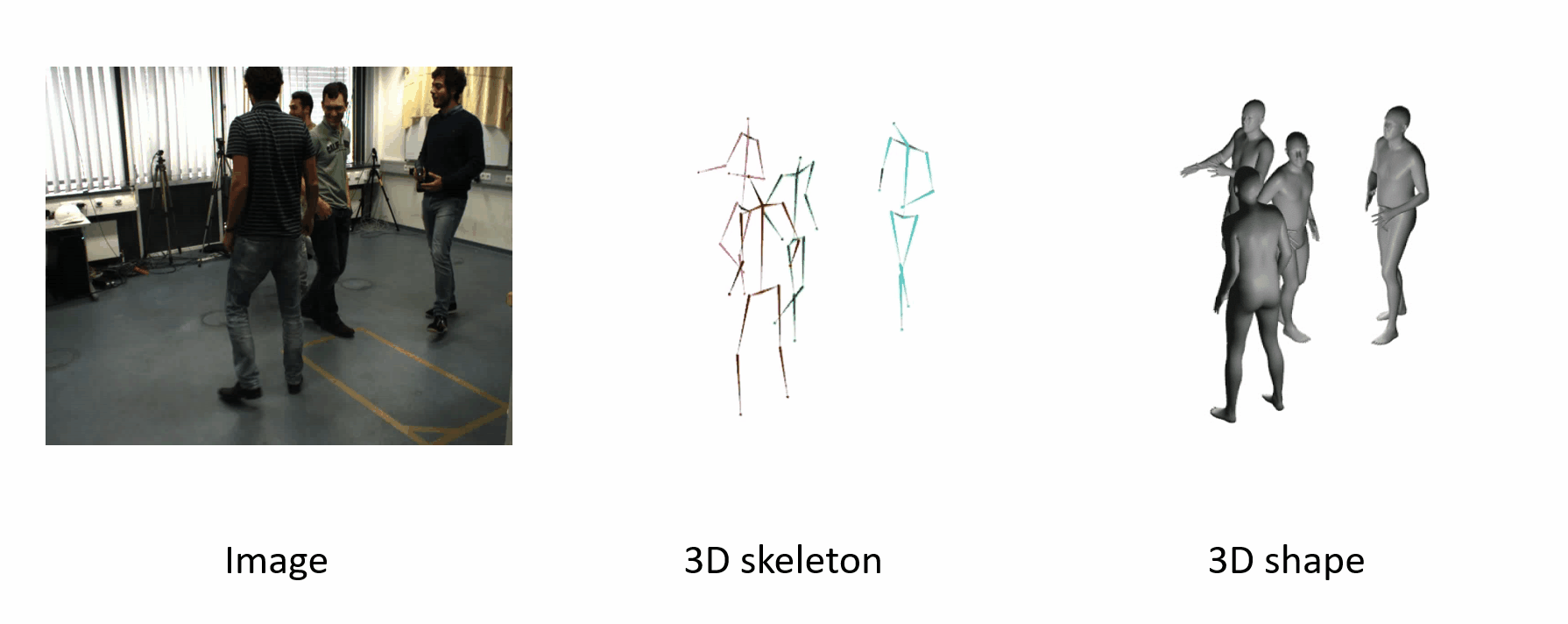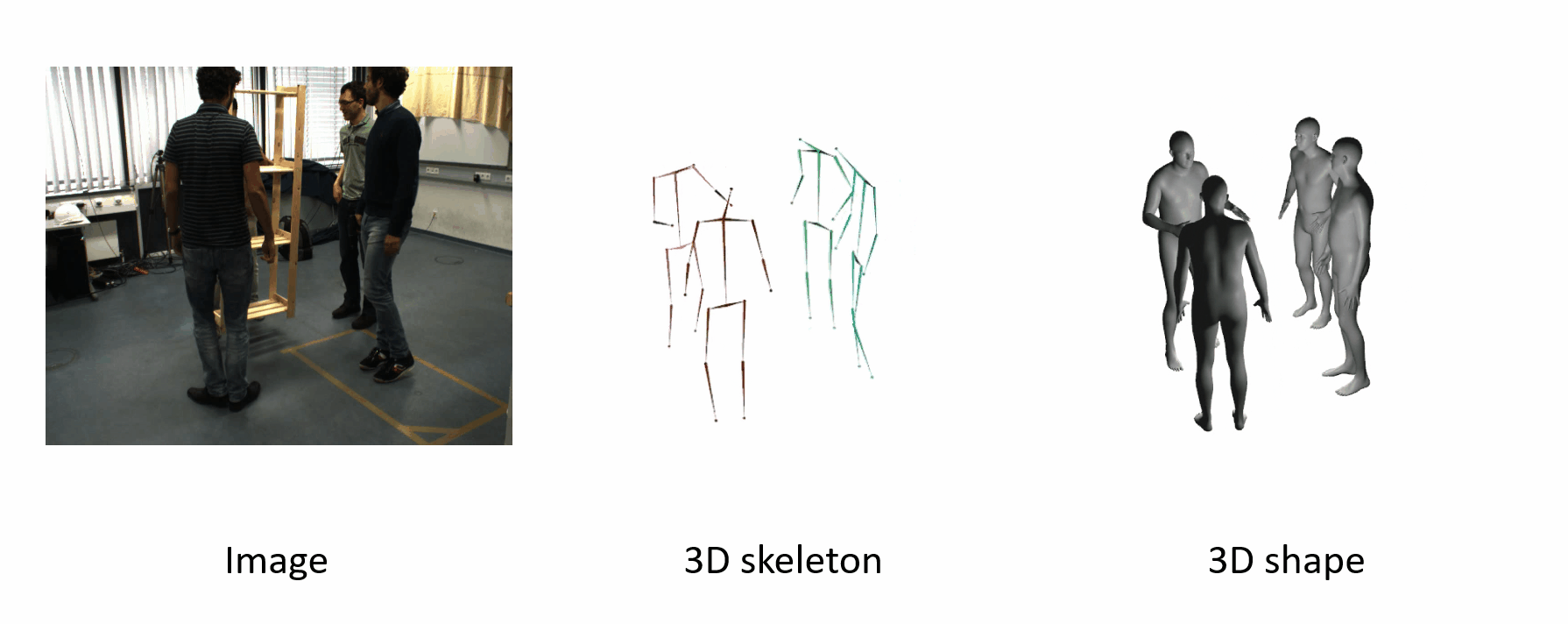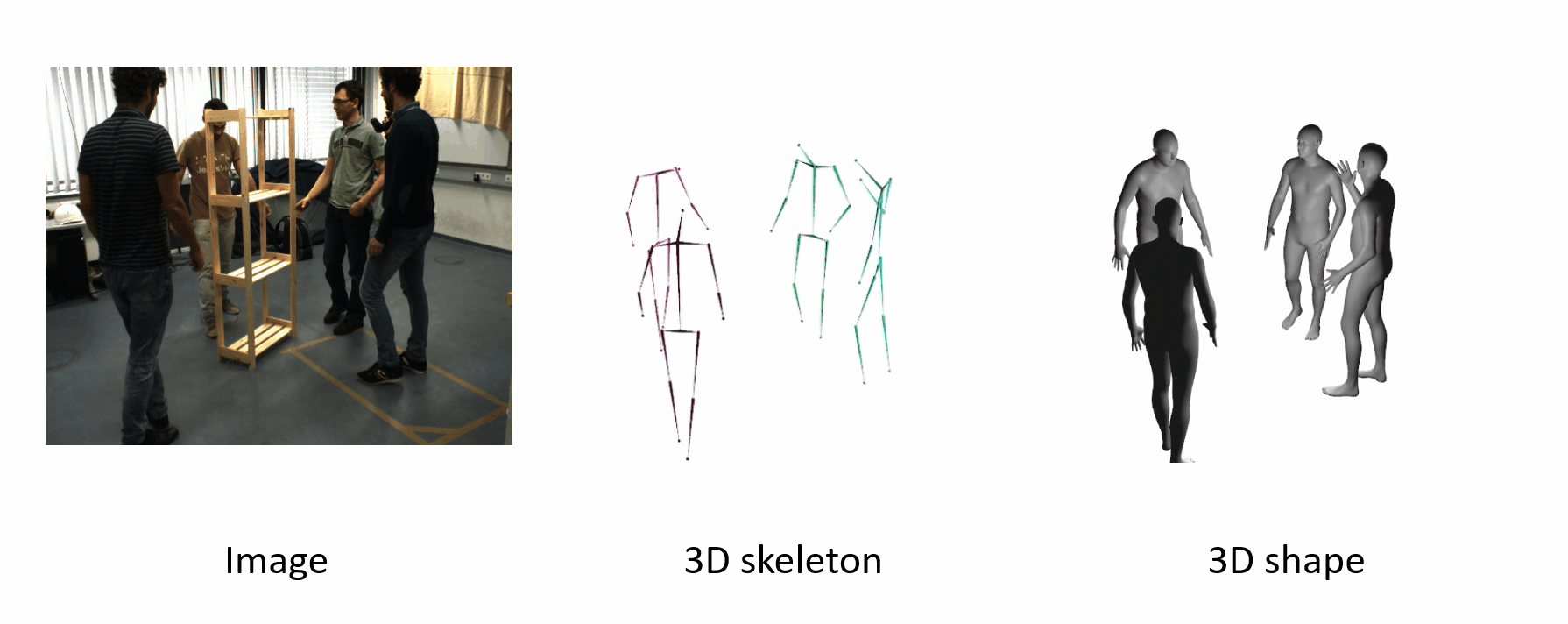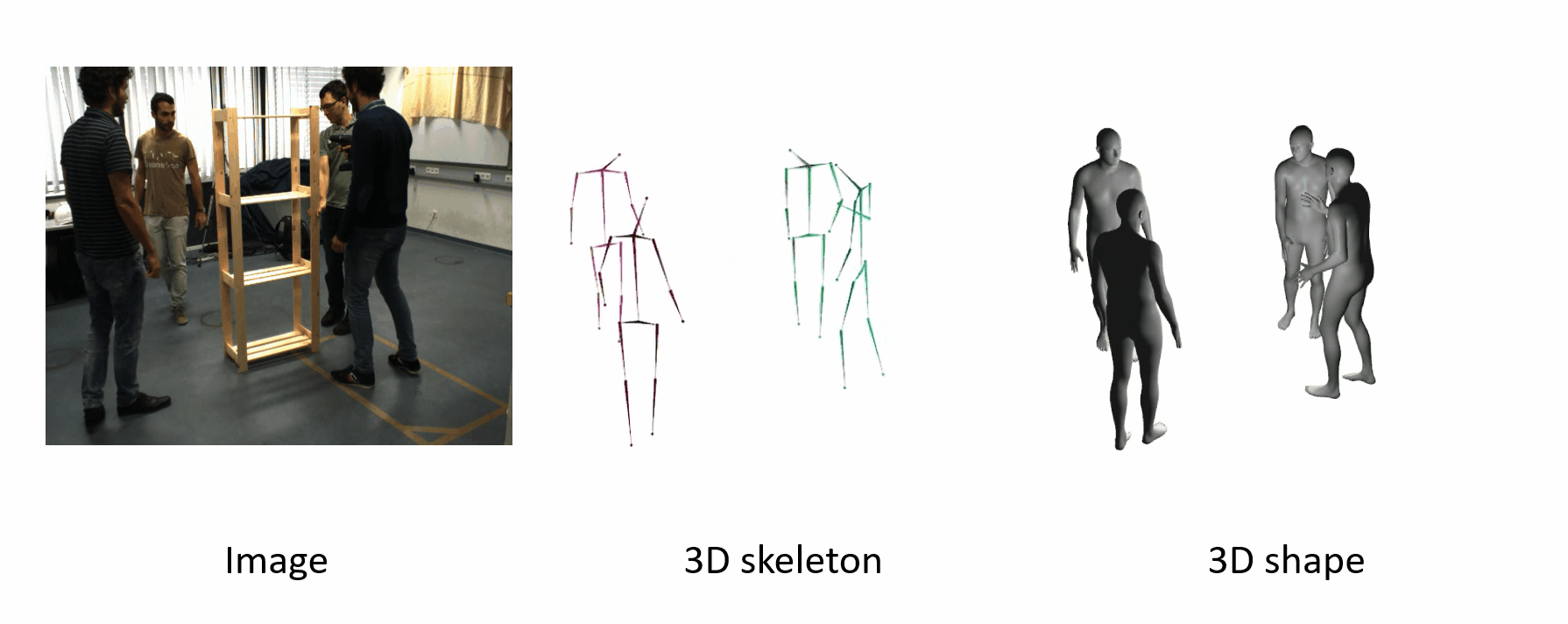
Here we show some results of our method. Our methods work even if the poses are uncommon.
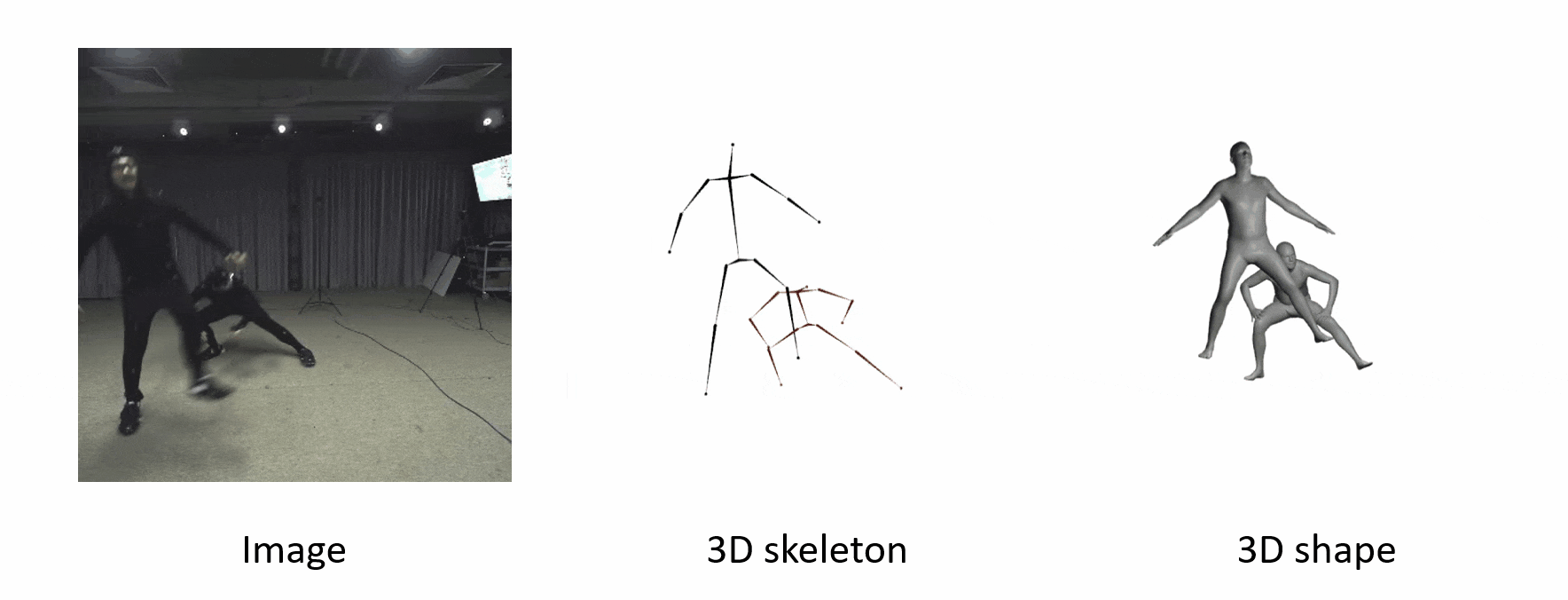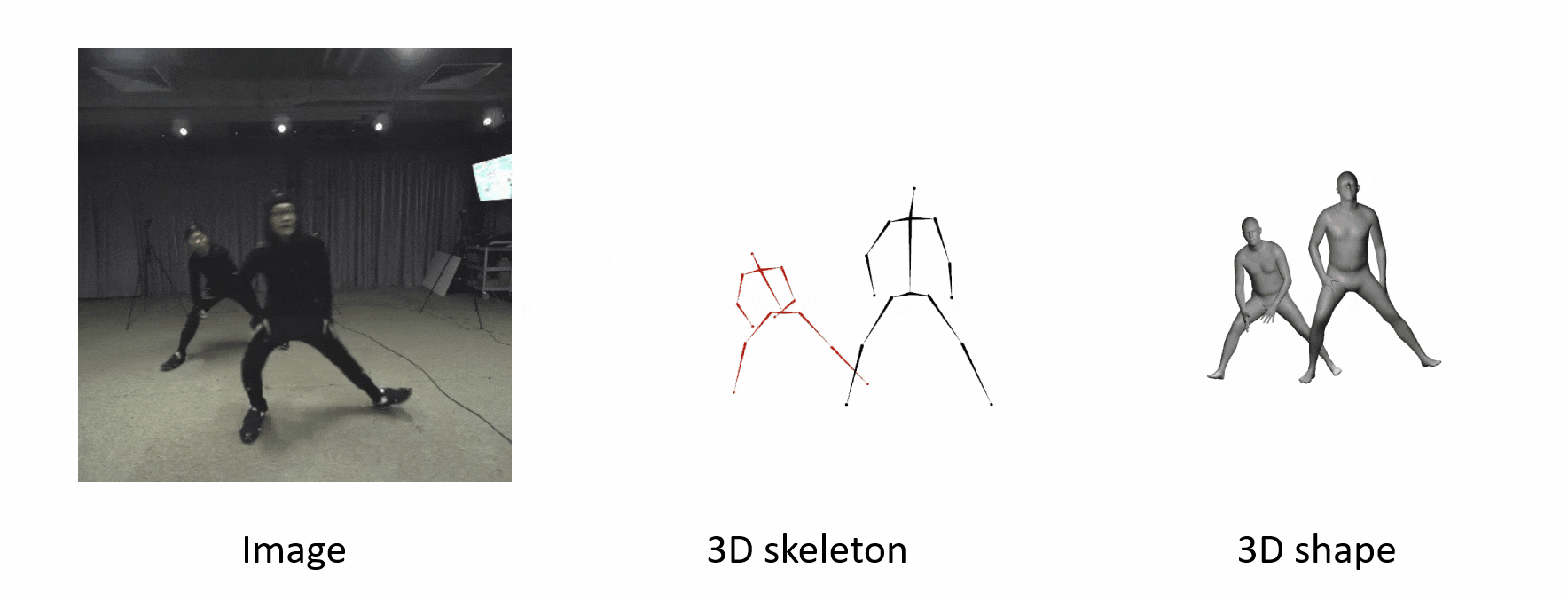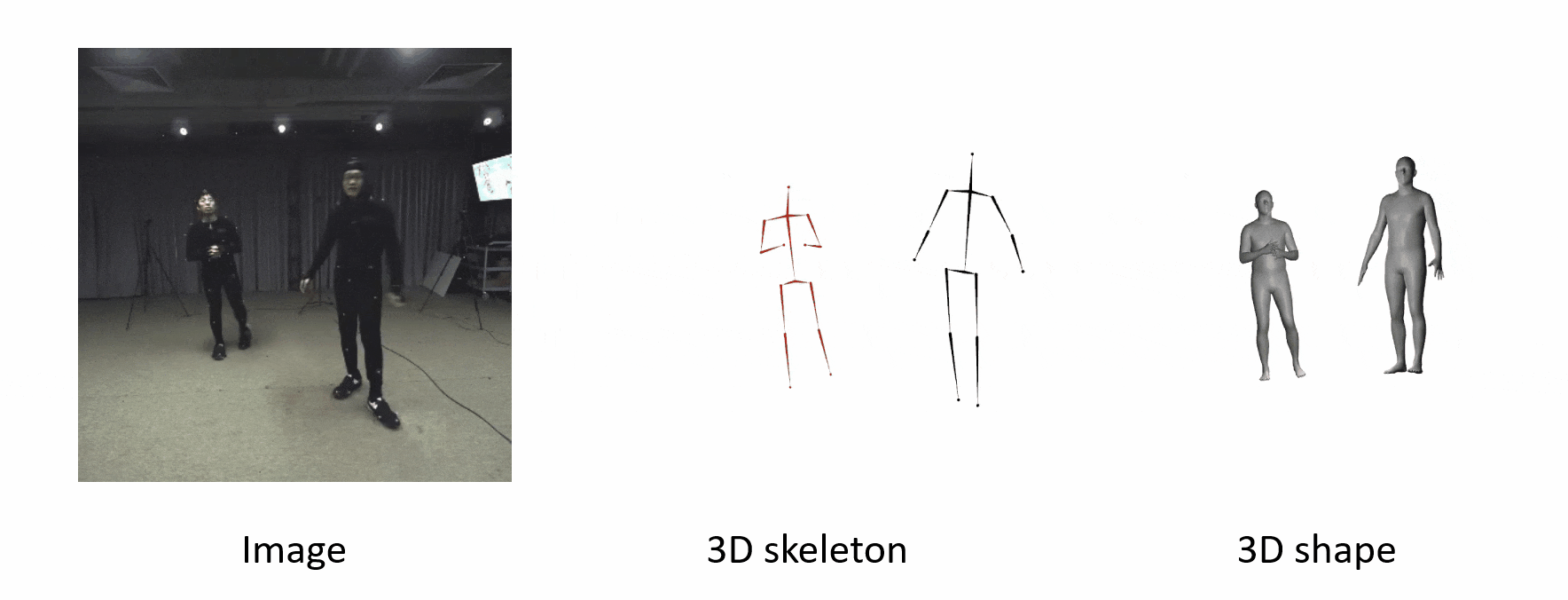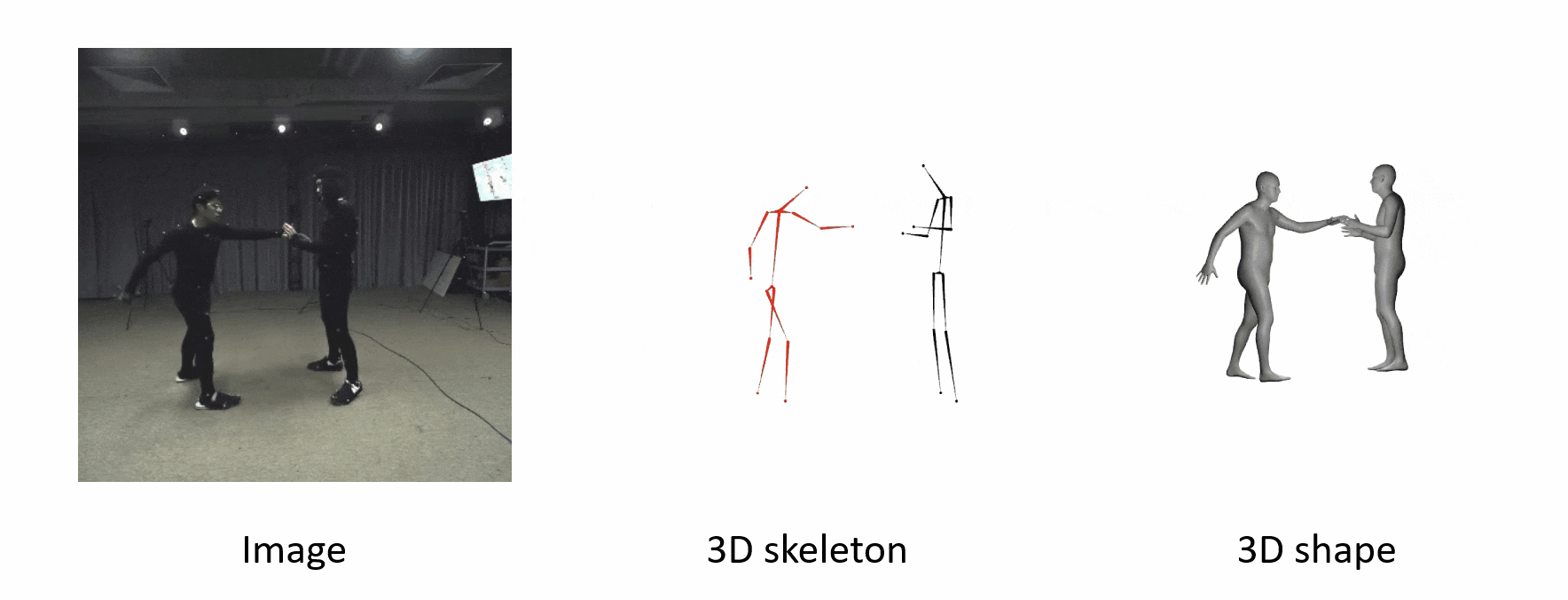
The algorithm is robust when people are occluded by each other.
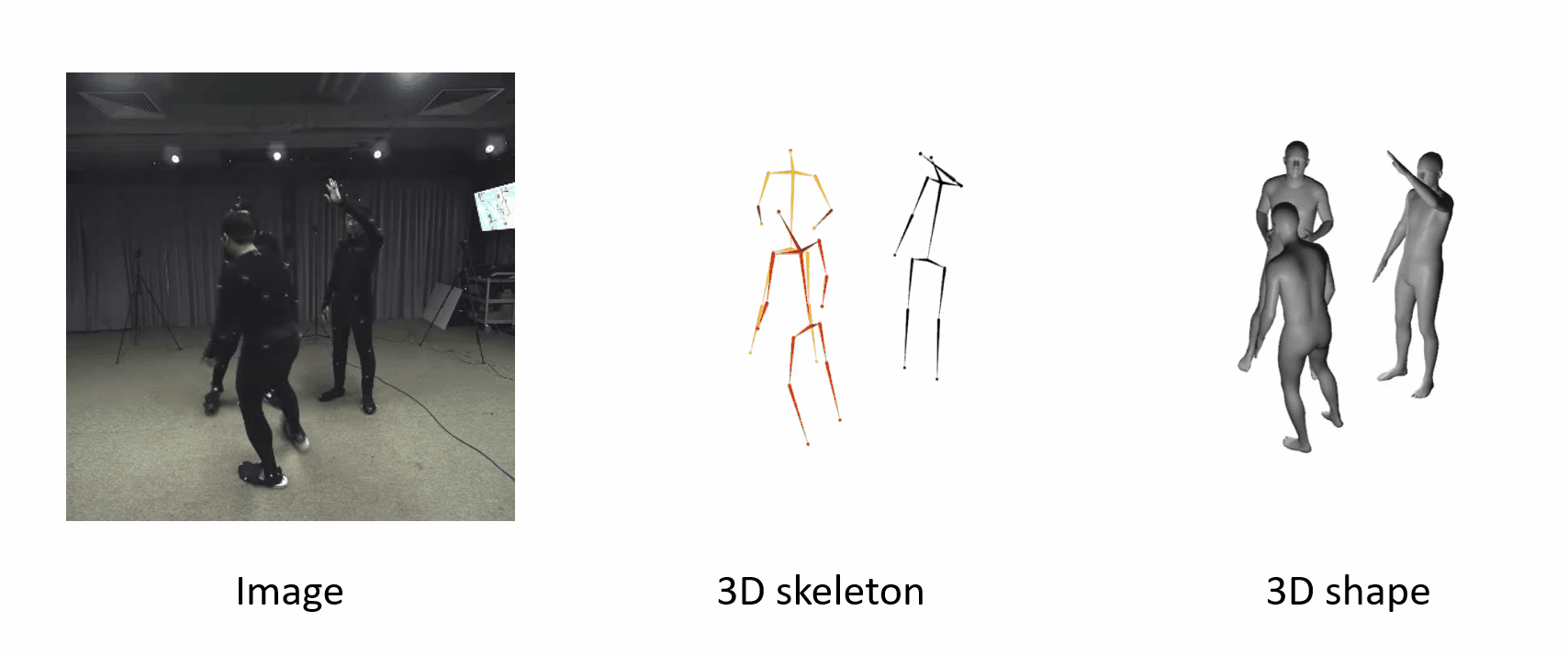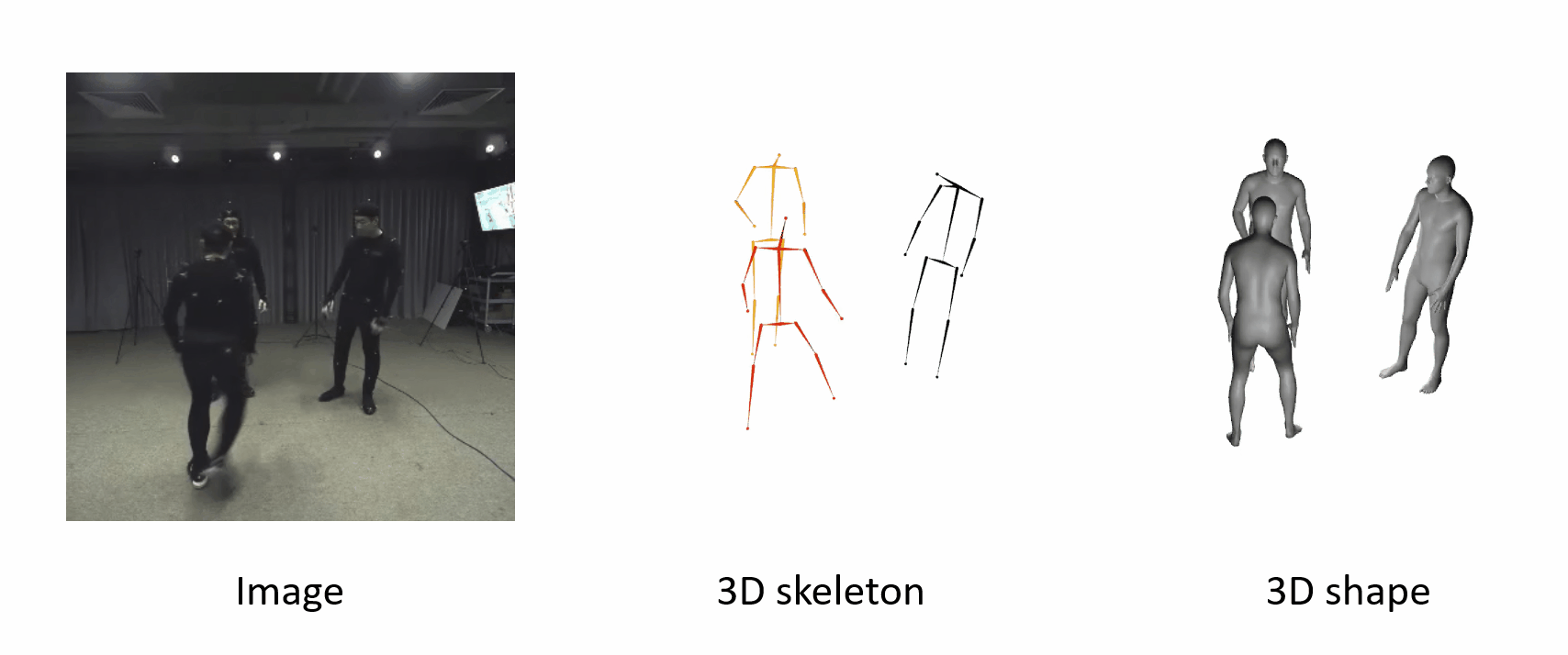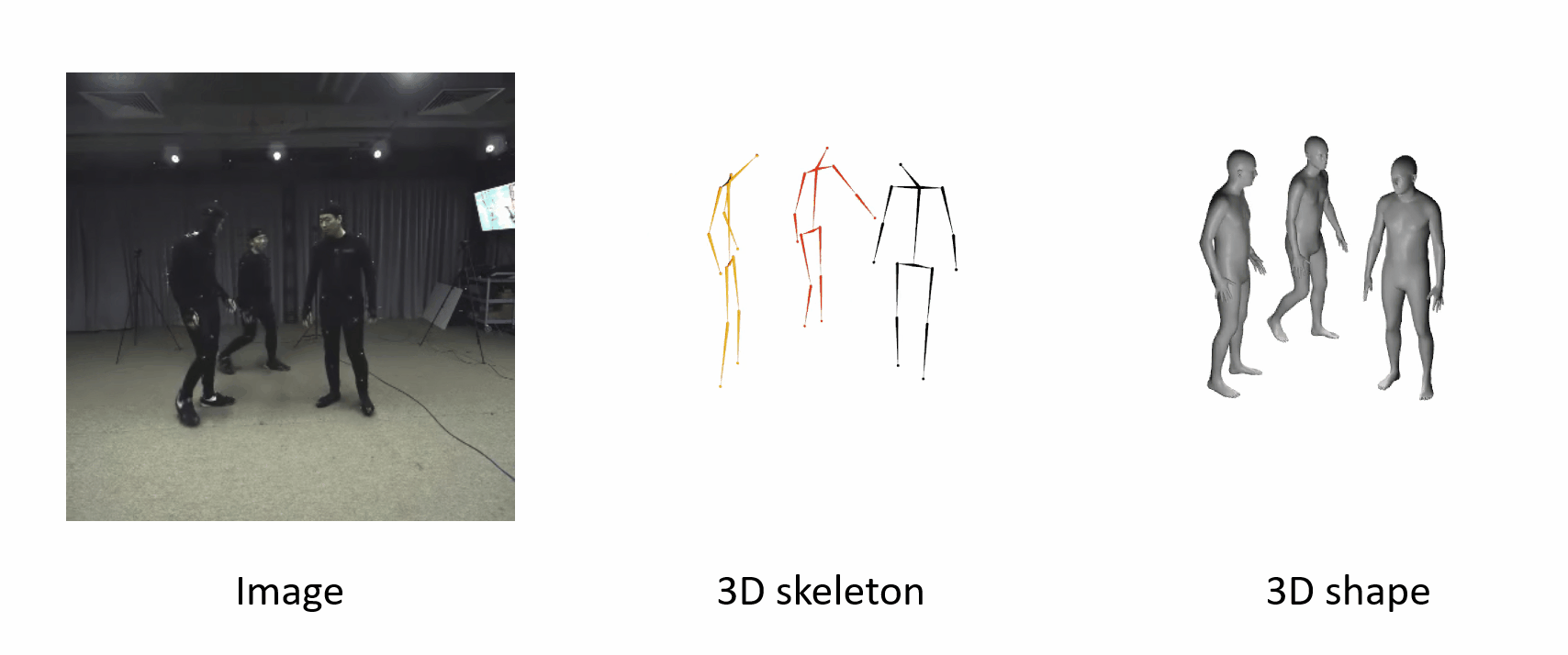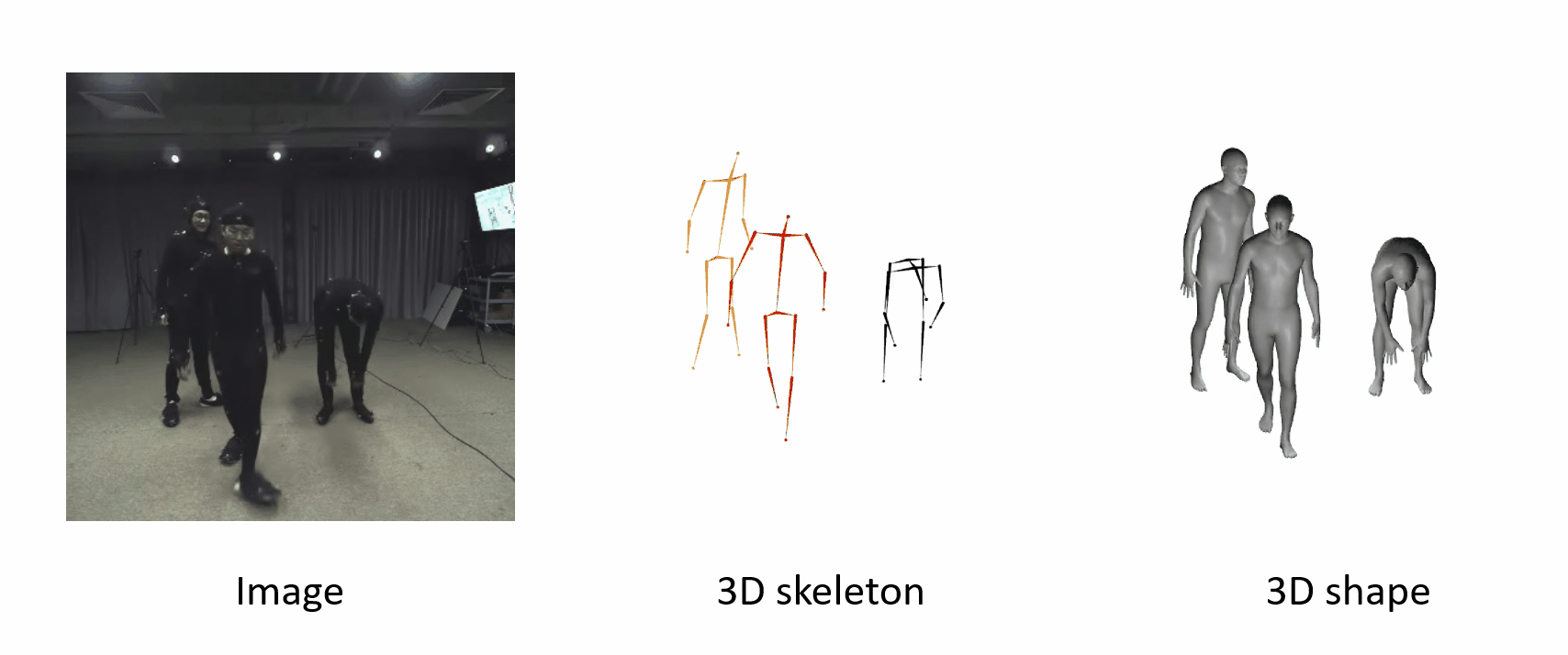
The poses are accurate when people move fast.
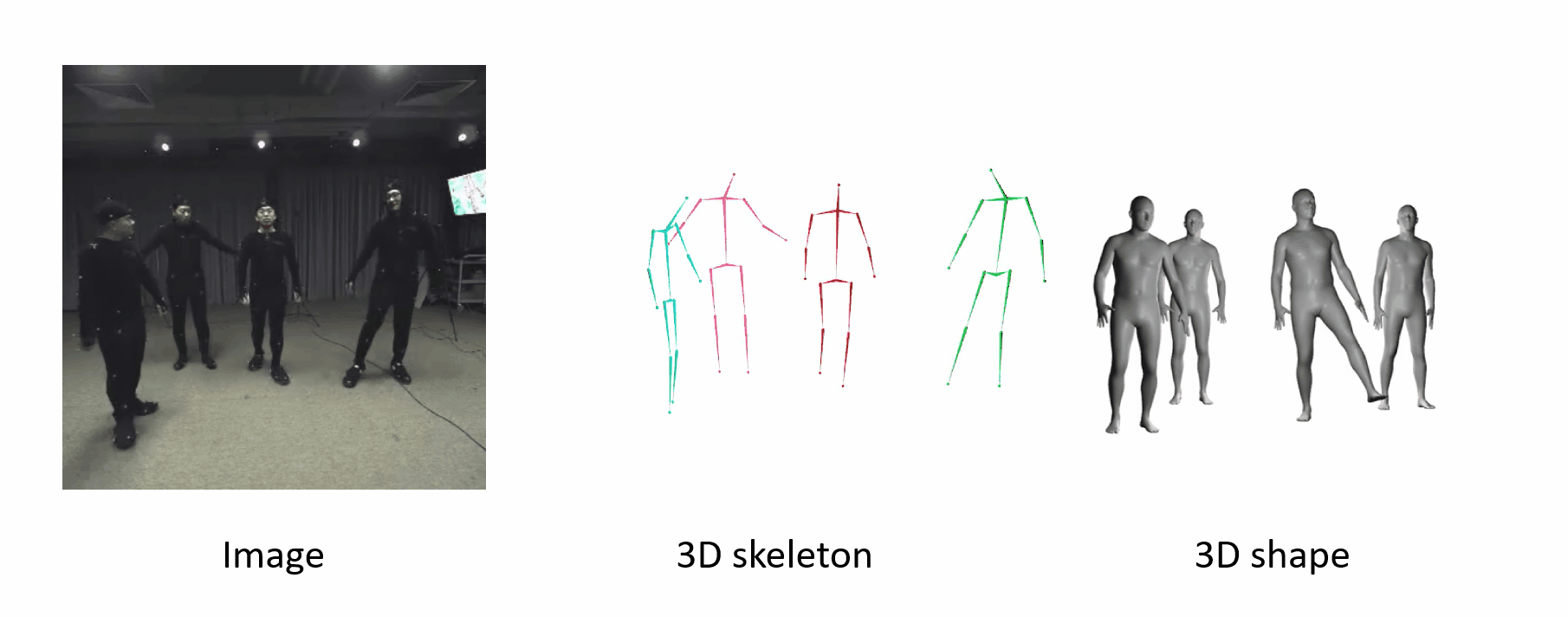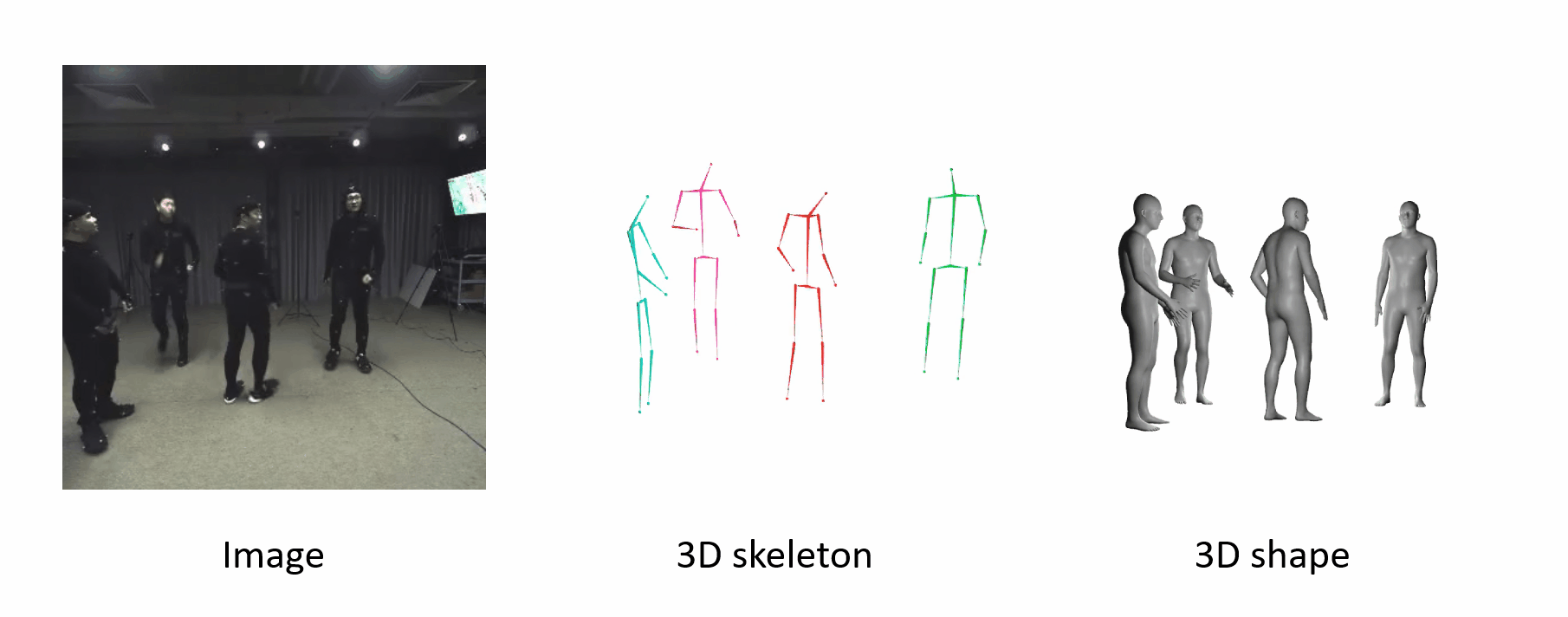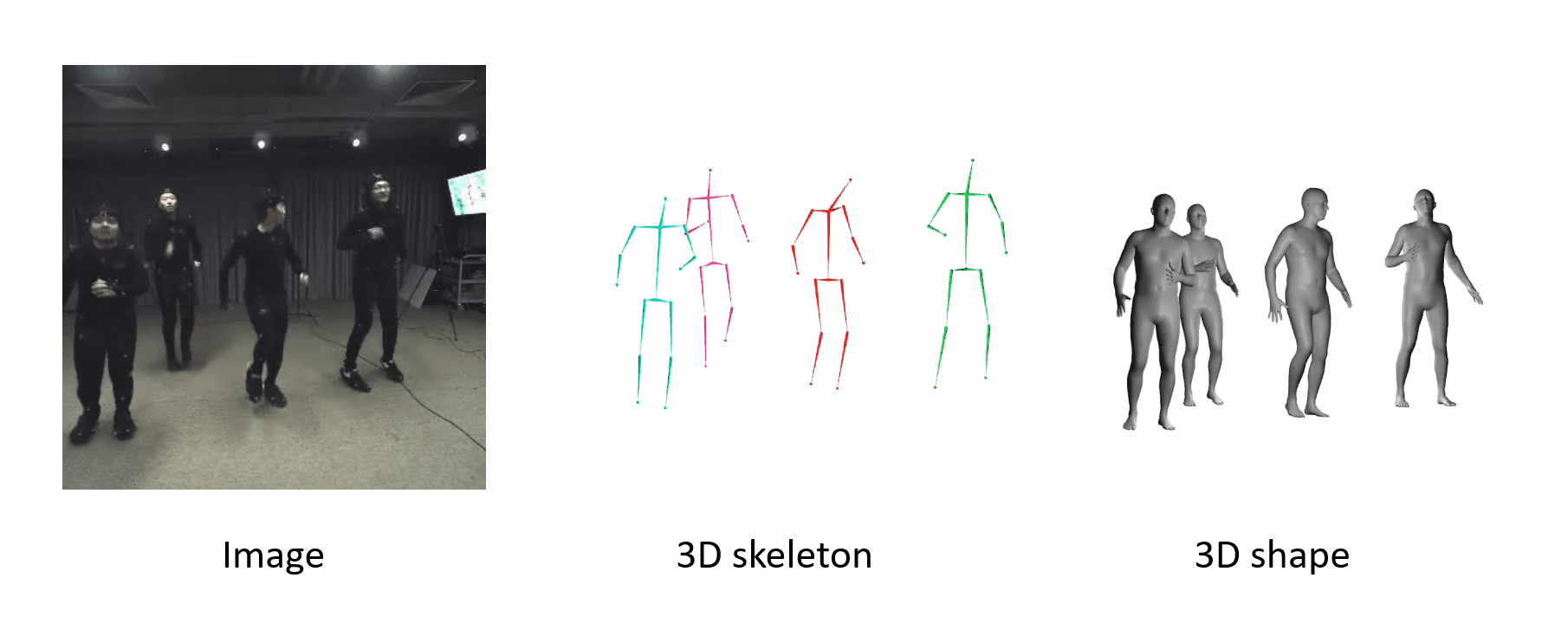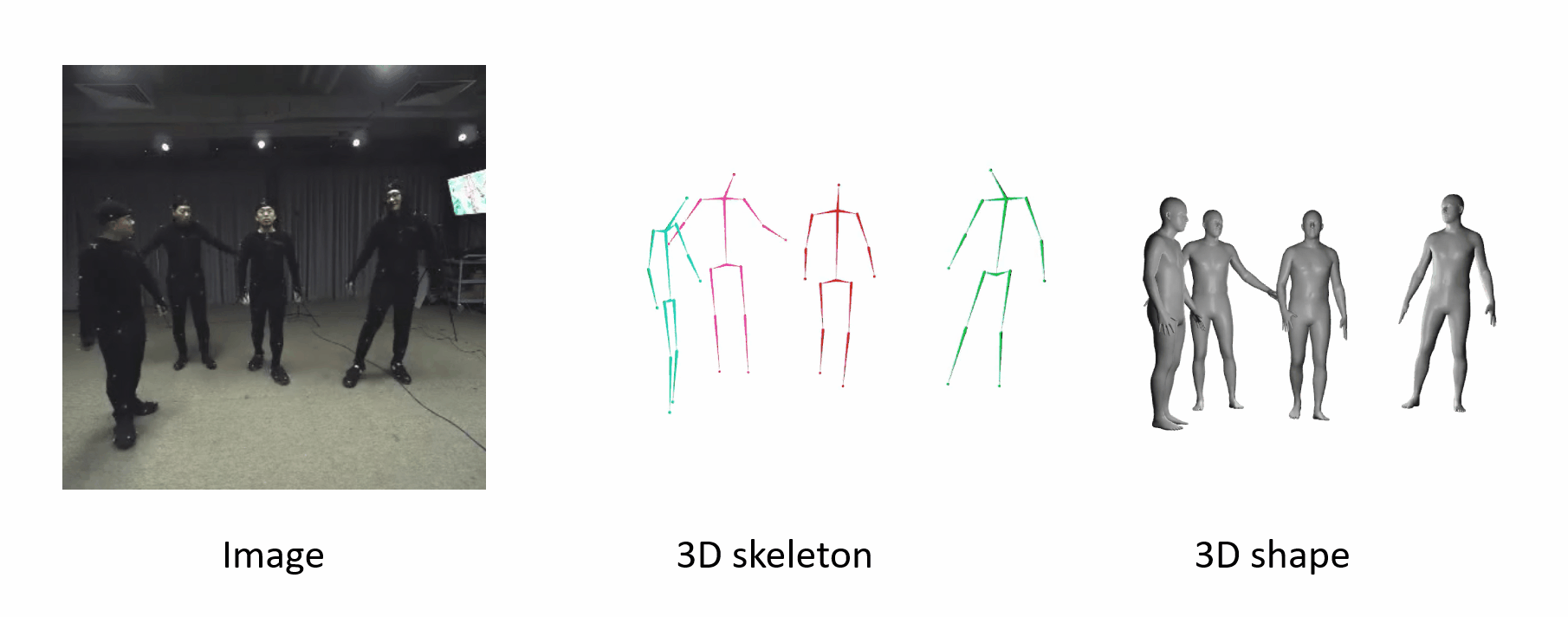
It can generalize to different datasets and scenarios.

Further Information:
Thanks for reading! To learn more about our project, watch our video here:
For more detailed information, check out the project page, the paper, and the supplementary! Code will be made available for research purposes via our project website. If you found our work helpful, please consider citing
@inproceedings{dong2021shape,
title={Shape-aware Multi-Person Pose Estimation from Multi-View Images},
author={Dong, Zijian and Song, Jie and Chen, Xu and Guo, Chen and Hilliges, Otmar},
booktitle={International Conference on Computer Vision (ICCV)}, year={2021}
}