PeCLR: Leverage unlabeled pose data with Pose Equivariant Contrastive Learning
In this blog post, we will be looking at using PeCLR, an equivariant contrastive loss formulation can make use of unlabeled hand pose data. We will be motivating why this is useful, show how this can be used to outperform state-of-the-art and hopefully convince you that self-supervised learning is a promising direction to pursue further in the context of hand pose estimation. These days, there is a vast amount of in-the-wild data displaying hands in action. Sources such as YouTube [1,2] or even just strapping a head-mounted camera [3] make it simple to acquire large-scale datasets that show diverse set of hands in wide range of settings. Let us look at two example of these:


Is there an effective way to use such data to improve neural network based hand pose estimation models?
To tackle this question, we will doing a high-level introduction of PeCLR. But first, we introduce some terminology.
Terminology
In the literature on self-supervision certain terms occur often. The first is pre-training, which refers to the act of training a neural network on a (usually large) corpus of unlabeled data via a self-supervised loss. This self-supervised loss is referred to as pretext task. The next term is fine-tuning, which refers to training the pre-trained model on a (generally smaller) set of labeled data using a supervised loss. The labeled data and loss define the downstream task, that is the task we are actually interested in solving or getting better at. Here, we are focusing on the downstream task of hand pose estimation. Equipped with this terminology, we are ready to have a high-level overview on PeCLR.
PeCLR: An equivariant contrastive loss formulation
PeCLR is a self-supervised contrastive learning method. It is based on SimCLR, which has shown impressive results on leveraging unlabeled data. Like SimCLR, PeCLR trains a neural network to increase alignment of latent samples of positive pairs of images, while decreasing it for negative pairs. Here the neural network produces the latent samples.
To create a positive pair, an image is sampled and two transformations are applied to it, resulting in two transformed images. As the creation of the positive pairs is done using batches of images, the negative samples of a given image are simply the transformed images of other images of the given batch. As we can see, this can be done entirely self-supervised. Hence we can apply this on a large corpus of unlabeled data.
Different to SimCLR, PeCLR induces equivariance with respect to affine transformations. To do so, it proposes the following pretext task. Given the two latent samples of a positive image pair, it undoes the affine transformations in latent space that resulted in the positive image pair and encourage maximal agreement between the untransformed samples:

Since this is a bit of a mouthful, let us try and gain some intuition on what is happening.
For simplicity, let us assume the only transformation applied is rotation. Hence, the two image samples forming the positive pair are rotated versions of an original image, using two randomly sampled rotation angles. Given their latent representation produced by our model, we invert the two rotations in latent space and encourage alignment between the inverse rotated latent samples. In order for the model to satisfy the this, it needs to project the latent samples in such a way that applying the inverse transformation yields aligned latent samples.
For example, if we have a positive pair where the samples are rotated by 10deg and 5deg clockwise, we rotate their latent samples by 10deg and 5deg counter-clockwise and encourage agreement. In order for the model to satisfy this loss, it needs to have a notion of rotation. More specifically, it needs to figure out by how much each image is rotated and project the latent sample accordingly. Hence, the model needs to project the sample equivariant to the rotation.
But wait, how do we exactly apply affine transformations onto latent samples as these are typically an n-dimensional vector? To do so, PeCLR reshapes the n-dimensional vector into a 2-by-n/2 matrix. The affine transformations are then applied on each column of this matrix. The matrix is then reshaped back into a vector before computing the similarity. The final PeCLR pipeline is as follows:

Results
Let us look at two main results of PeCLR. Reminding ourselves of original goal of leveraging unlabeled data, we ask how will pre-training on large amount of unlabeled images affect the performance of a hand pose estimator. Lets take a closer look.
We train a RN50 and RN152 from scratch and from a PeCLR pre-trained model. Specifically, the PeCLR model was pre-trained self-supervised on FreiHAND (FH) and YouTube3DHands (YT3D) and fine-tuned on FH. In the following table, we see the final performance:
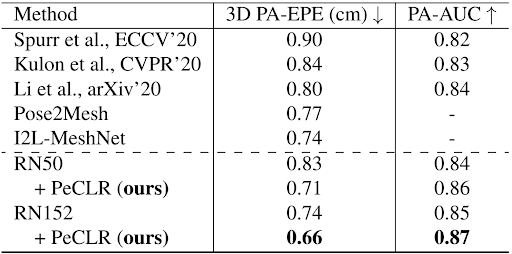
We make three key observations. First, neither base models achieve state-of-the-art, where RN152 reaches parity (using more model capacity as prior work). Second, the PeCLR pre-trained model leads to a decrease in procrustes-aligned end-point-error (PA-EPE) of 14.5%/10.8% for RN50 and RN152 respectively. Lastly, this boost in performance leads to state-of-the-art performance for both networks. These results provide empirical evidence that pre-training on unlabeled data improves the performance of a hand pose estimator.
But do these results generalize across datasets? To shine further light on this, we run the best performing model of the previous experiment on YT3D and inspect its performance.
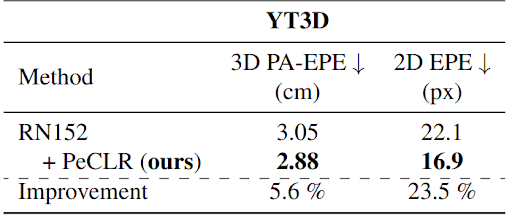
Excitingly, this experiment provides evidence that the improvements seem to not only hold on the target dataset, but also across datasets!
Conclusion
We thank you for reading this high-level introduction on PeCLR and hope to have demonstrated the potential of our approach on improving pose estimation methods. For further information, we encourage you to read our paper, watch our video and to take a look at the project page. Code and pre-trained models are made available for research purpose. If our work was helpful for your research, please consider citing:
@inProceedings{spurr2021peclr,
title={Self-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning},
author={Spurr, Adrian and Dahiya, Aneesh and Wang, Xi and Zhang, Xucong and Hilliges, Otmar},
booktitle={International Conference on Computer Vision (ICCV)},
year={2021}
}