EM-POSE: 3D Human Pose Estimation from Sparse Electromagnetic Trackers

AR and VR is a promising computing platform for entertainment, communication, medicine, remote presence and more. An important component of an immersive AR/VR experience is a method to accurately reconstruct the full body pose of the user. While pose estimation from consumer cameras has progressed impressively over recent years, the requirement for external cameras inherently limits the mobility of the user. Body-worn sensors bear the promise to avoid this limitation but bring their own set of challenges. In this work, we study the use of electromagnetic (EM)-based sensing with 6–12 customized wireless EM sensors that have no line-of-sight constraints.
EM Sensing Principle

EM-based tracking has been around for some time; early military applications date back to the 1960s. In EM sensing, a source emits an electromagnetic field in which a sensor can determine its position and orientation relative to the source. There are many existing EM-based tracking systems available on the market, which differ in supported tracking range, update rate and form factor of the hardware. For our specific use case (full body tracking) we have found that existing solutions are not well suited as they either involve large sensors or use tethered sensors which encumbers movement. We have thus developed a custom EM tracking system that uses up to 12 small, wireless EM sensors that are tuned to operate within a 0.3–1 meter range around the source. This allows us to mount up to 12 sensors on a human body as shown in the figure above.
In a typical usage scenario, we have found that an individual sensor’s accuracy is usually within 1 cm positional and 2–3 degrees angular error compared to optical marker-based tracking (Optitrack). However, compared to optical tracking, our EM sensors have no line-of-sight constraints.

The Task

While designing an EM-based tracking system with up to the 12 small, wireless, and time-synchronized sensors is a challenge on its own, we still need to address the question how we can reconstruct body pose and shape from these EM measurements. This is the task that we are studying in this work. More specifically, given n positional and orientational measurements, summarized as x, we want to find a function that maps these inputs to body pose and shape, which in our case are SMPL parameters, denoted as Omega.
This is challenging for several reasons. First, although EM-sensing can be highly accurate, the accuracy of a sensor depends on its distance from the source. In our case, this makes our input measurements pose-dependent.
Second, ideally we’d like to instrument the human body as little as possible. To do so, we can reduce the sensor count by half and just use the 6 sensors on forearms, lower legs, upper back, and head. This, however, leaves the body pose underconstrained (e.g. the movement of the left upper arm is no longer directly observed). Thus, the resulting method should be able to infer certain unobserved joints based on how the available reduced sensor set moves.
Third, when we mount sensors on a user’s body, there will be sensor-to-skin offsets which vary between participants. Furthermore, because of the pose-dependent accuracy of the EM sensors, and because sensors might inadvertently slip against the skin during exercise, these offsets can vary over time. Hence, the proposed method should be robust to such changes such that we can provide a single model for multi-person 3D pose and shape estimation.
This is why we have chosen a Learned Iterative Fitting approach, which is a hybrid of learning- and optimization-based methods. The learning-part helps us to harness powerful pose priors to address some of the challenges above, while the optimization part allows for pushing the accuracy of the predictions. The inner workings are explained in a bit more detail in the following.
Learned Iterative Fitting
To estimate SMPL pose and shape from 6–12 EM measurements, x, we adopt the recently proposed Learned Gradient Descent framework. In LGD, we first define a reconstruction loss which we aim to minimize:
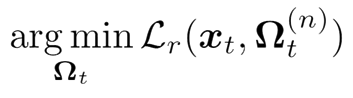
This loss measures how well the inputs, x, can be reconstructed from the current estimate of SMPL pose and shape, Omega. To implement this reconstruction loss, we define a function that computes virtual EM measurements given Omega.
Instead of minimizing the reconstruction loss in a traditional way, LGD employs a per-parameter update rule whereby the gradient is estimated by a neural network, N.
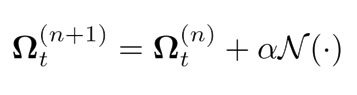
This allows for fast convergence in typically 4 iterations. To provide the initial estimate of Omega, we feed the inputs to an RNN. Thus, a complete overview of our method is as follows.
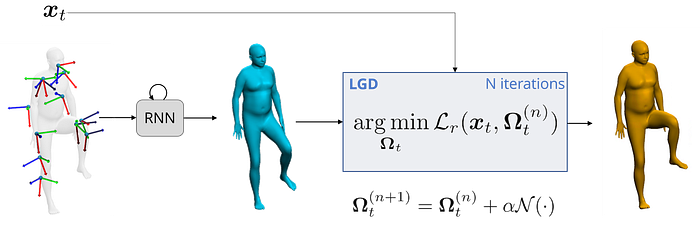
To reap the benefits of LGD, we must train the neural network N. This requires a large-scale dataset that pairs EM measurements with SMPL poses, which is expensive to acquire. Instead, we capture a smaller, real dataset for evaluation purposes and use AMASS to synthesize virtual EM measurements, which we use to train N. By extracting user-specific skin-to-sensor offsets from a dedicated real calibration sequence, we can augment the training data in such a way that the final model generalizes well to multiple as well as unseen participants without the need for further domain adaptation techniques.
Newly Captured Dataset
As mentioned above, we capture a new dataset consisting of pairs of EM measurements and SMPL poses to evaluate our method. The dataset contains roughly 37 min of motion (approx. 66k frames) and was recorded with 3 female and 2 male participants. To obtain SMPL parameters, we use RGB-D data from 4 Azure Kinects in an offline multi-stage optimization procedure. Recorded motion types include arm motions, lunges, squats, jumping jacks, sitting, walking around and more. The data will be made available for download. For more details please visit our project page.
Results
To evaluate our method on our dataset, we train two models: one using 6 sensors as input and one with the full 12 sensor setup. We have experimentally found that the hybrid LGD-based method outperforms both pure learning-based and pure optimization-based methods. This highlights the benefits of LGD: it provides accurate pose estimates while still being orders of magnitude faster at inference time compared to pure optimization.
With 12 sensors in the input, we achieve reconstruction errors as low as 31.8 mm or 13.3 degrees. When using the reduced 6-sensor set, performance naturally drops a bit to 35.4 mm or 14.9 degrees, but still remains very competitive.
A visualization of our results is best viewed in our supplementary video:
More Information
Thank you for reading! If you are interested in more details, we invite you to check out our paper, video, or project website. Code and data will be made available for research purposes via our project website. If you found our work helpful, please consider citing
@inProceedings{kaufmann2021empose,
title={EM-POSE: 3D Human Pose Estimation from Sparse Electromagnetic Trackers},
author={Kaufmann, Manuel and Zhao, Yi and Tang, Chengcheng and Tao, Lingling and Twigg, Christopher and Song, Jie and Wang, Robert and Hilliges, Otmar},
booktitle={International Conference on Computer Vision (ICCV)},
year={2021}
}Acknowledgements
This is work in collaboration with Facebook Reality Labs.